
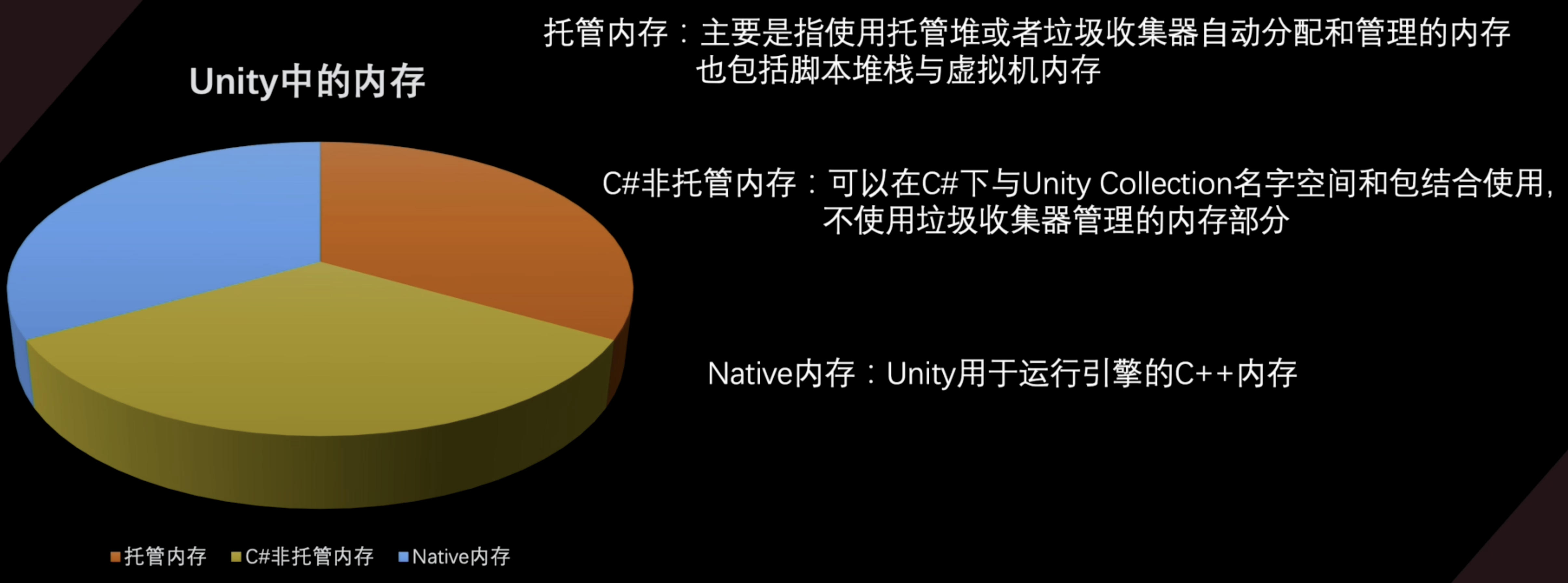
托管内存
托管堆内存通常是优化的主要方面,托管内存使用方便,但释放与内存分配方式不可预期。Unity使用的是保守的 回收器
C#非托管内存
可以访问Native内存层,进行native内存的微调。使用Unity.Collections包
Profiler
默认的 Profiler中并不全,可以在Profiler Modules 中添加自定义的模块
Memory Profiler
其他
对于无法通过Unity抓取到的内存,如一些 Plugins 等,我们可以使用 XCode 或者 安卓中的命令行进行调试
XCode
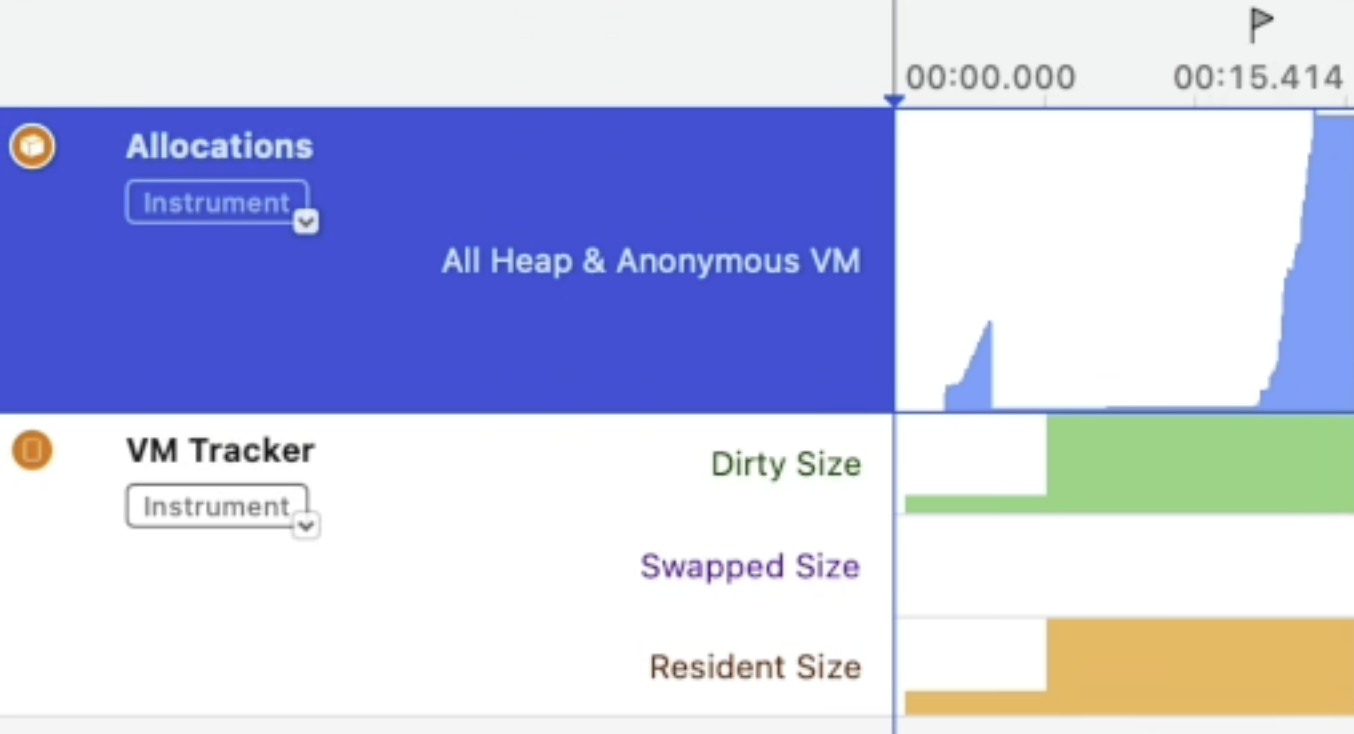
VMTracker
- Swapped Size 不活跃的内存,可以被交换到磁盘上的大小(可以被卸载的大小)非Dirty才能被交换或卸载
- Resident Size 使用的物理内存量
- Dirty Size 物理内存中不能被复用或卸载的内存块,非常重要,观察峰值是否超过警戒线
Native内存分配器详解
C++层会根据用处不同,抽象成不同Allocator进行内存分配 Memory Setting中可以查看一部分
按用途分类
- Main Allocators:绝大多数内存分配使用的
- Fast Per Thread Temporary Allocators:线程上使用的临时分配器,如音乐、渲染、预加载、烘焙
- Fast Thread Shared Temporary Allocators:线程间共享临时分配器
- Profiler Allocators
按底层类型分类
- UnityDefaultAllocator
- BucketAllocator
- DynamicHeapAllocator
- DualThreadAllocator
- TLSAllocator(Thread Local Storage)
- StackAllocator
- ThreadSafeLinearAllocator
- 。。。各个平台特性的分配器或调试分配器等 按用途分类的分配器与底层分类的关系是 一对多
| 分配器类型 | 分配器算法 | 用途 |
|---|---|---|
| Bucket 桶分配器 | Two Level Segregated Fit (TLSF) | - Main allocator - Gfx allocator - Typetree allocator - File cache allocator - Profiler allocator - Editor Profiler allocator (on Editor only) |
| Dynamic Heap动态堆分配器 | Fixed size lock-free allocator | As a shared allocator for small allocations for: - Main allocator - Gfx allocator - Typetree allocator - File cache allocator |
| Dual thread | Redirects allocations based on size and thread ID | - Main allocator - Gfx allocator - Typetree allocator - File cache allocator |
| Thread Local Storage(TLS) stack | LIFO stack | Temporary allocations |
| Threadsafe linear | Round robin FIFO | Buffers for passing data to jobs |
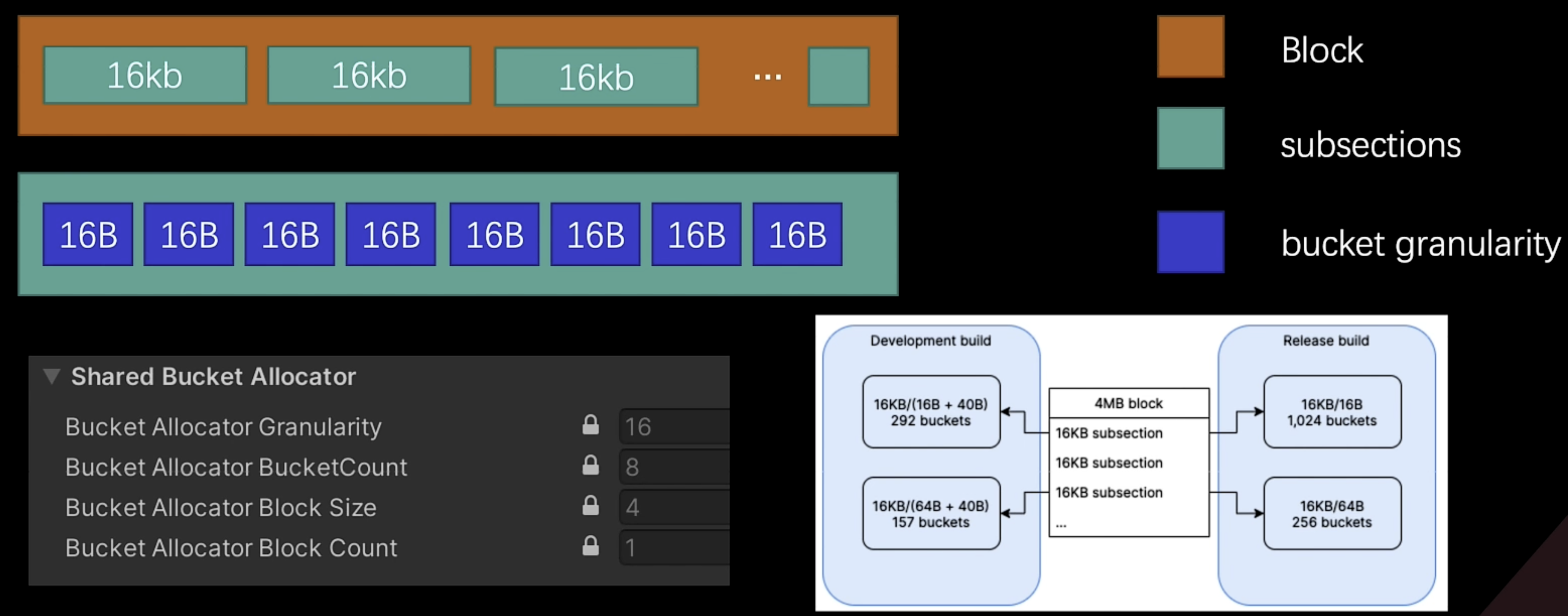
BucketAllocator(桶分配器)
- 每个bucket由固定大小粒度granularity表示,如果granularity为16字节大小,则用于分配16/32/48/64/···字节的内存,如果是development版本granularity在设置大小的基础上增加40个字节
- 分配器为分配保留内存块Block,每个块被划分为16kb的子段(subsections),并且不可配置。Block块只能增长,并且需要是固定16kb大小的整数倍。
- 分配是固定大小无锁的,速度快,通常作为进入堆分配器之前用来加速小内存分配的分配器
- Log日志中可以通过查看[ALLOC_BUCKET]字段来看是否有Failed Allocations.Bucket layout字段,以及Peak Allocated bytes字段与Large Block size字段的利用率,来判定大小是否分配合适,
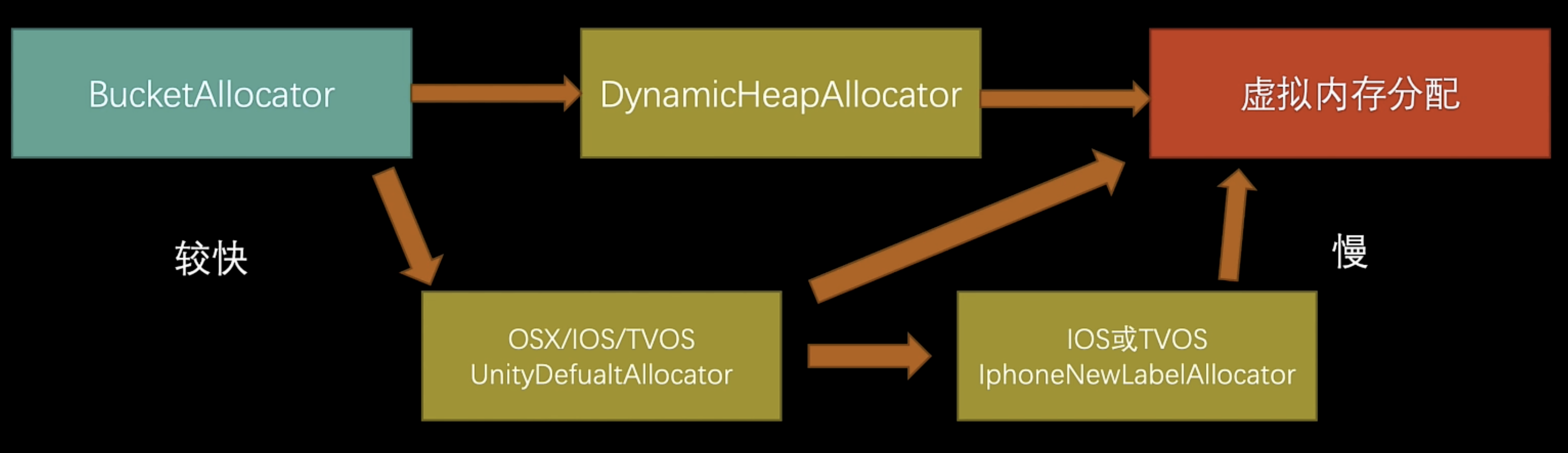
- 分配失败会会退到DynamicHeapAllocator或UnityDefaultAllocator分配器上,效率变差。
DynamicHeapAllocator(动态堆分配器)
- 所有平台都希望使用的分配器(Mac与lOS暂时仍然使用UnityDefaultAllocator)
- 底层基于TLSF,保留TLSF块列表,并在一个块已满后,切换到另一个块,或没有时分配一个新块,关于TLSF :http://www.gii.upv.es/tlsf/files/ecrts04_tlsf.pdf
- 最棘手的部分是设置块的大小。根据不同平台,更大的块效率更高,碎片更少,但对于内存有限的平台来说灵活性差
- 最大块为256M,最小块为128k,如果64位架构使用更大的Region来保存多个块MEMORY_USE_LARGE_BLOCKS,如果分配失败会会退到虚拟内存分配,效率更差
- Log中[ALLOC_DEFAULT_MAIN]下关注Peak usage frame count字段,查看大多数帧分配内存的范围,关注内存分配峰值Peak Allocated memory字段,以及Peak Large allocation bytes没有使用TLSF分配的内存大小 ,是否超过block个数* block块大小
DualThreadAllocator
- 它是将2个DynamicHeapAllocator实例与1个BucketAllocator封装到一起,其中BucketAllocator负责小的共享内存分配,1个无锁的DynamicHeapAllocator用于主线程分配,另外一个DynamicHeapAllocator负责其他线程的共享分配,但是分配与回收时需要加锁
- Log中[ALLOC_DEFAULT]下分别关注[ALLOC_BUCKET]、[ALLOC_DEFAULT_MAIN]、[ALLOC_DEFAULT_THREAD]字段下一个BucketAllocator与2个DynamicHeapAllocator的分配信息,其中尤其关注Peak main deferred allocation count字段,这个字段代表需要在主线程回收的分配队列。
- 负责其他线程的共享分配的DynamicHeapAllocatord对应C#非托管内存的Allocator.Persistent
TLS Stack Allocator
- 用于快速临时分配的堆栈分配器。它是最快的分配器,几乎没有开销,并且可以防止内存碎片,对应C#非托管内存的Allocator.Temp分配类型
- 它是基于后进先出LIFO的算法,分配的内存生命周期在一帧内。
- 如果分配器使用超过了配置的大小,Unity会增加分配块大小,但会是配置设置的2倍大小,
- 如果线程堆栈分配器满了,分配器将会退到线程安全线性job分配器。这时一帧内允许有1-10分配,甚至如果是加载期间可以允许几百次。但如果每帧的分配数字增加可以考虑增加块大小。
- Log日志[ALLOC_TEMP_TLS]下关注[ALLOC_TEMP_MAIN]与[ALLOC_TEMP_Job.Worker xx] 中 的Peak usage frame count于Peak Allocated Bytes字段,也要关注Overflow Count字段,是否发生了分配器溢出会退的情况。
Thread SafeLinearAllocator

- 用于快速无锁分配Job线程的缓冲区,并在Job完成后释放缓冲区,对应C#非托管内存的Allocator.TempJob
- 采用循环先进先出FIFO算法,先分配内存块,然后在这些内存块内进行线性分配内存所有可用块都会存到一个池中,当一个块满时再从池中提取一个新的可用块。当分配器不再需要块中内存时,清理该块并放回到可用池中。快速清理分配可用块非常重要因此Job的分配尽量在几帧内完成。
- 如果所有块都在使用中,或者一个分配对于一个块太大的情况下,则会退到主堆分配器,分配效率会下降。
- Log日志[ALLOC_TEMP_JOB_4_FRAMES]中我们需要关注Overflow Cout(too large)与Overflow Count(full)字段,判断是否发生了分配器溢出会退。
工作线程分配器回退流程
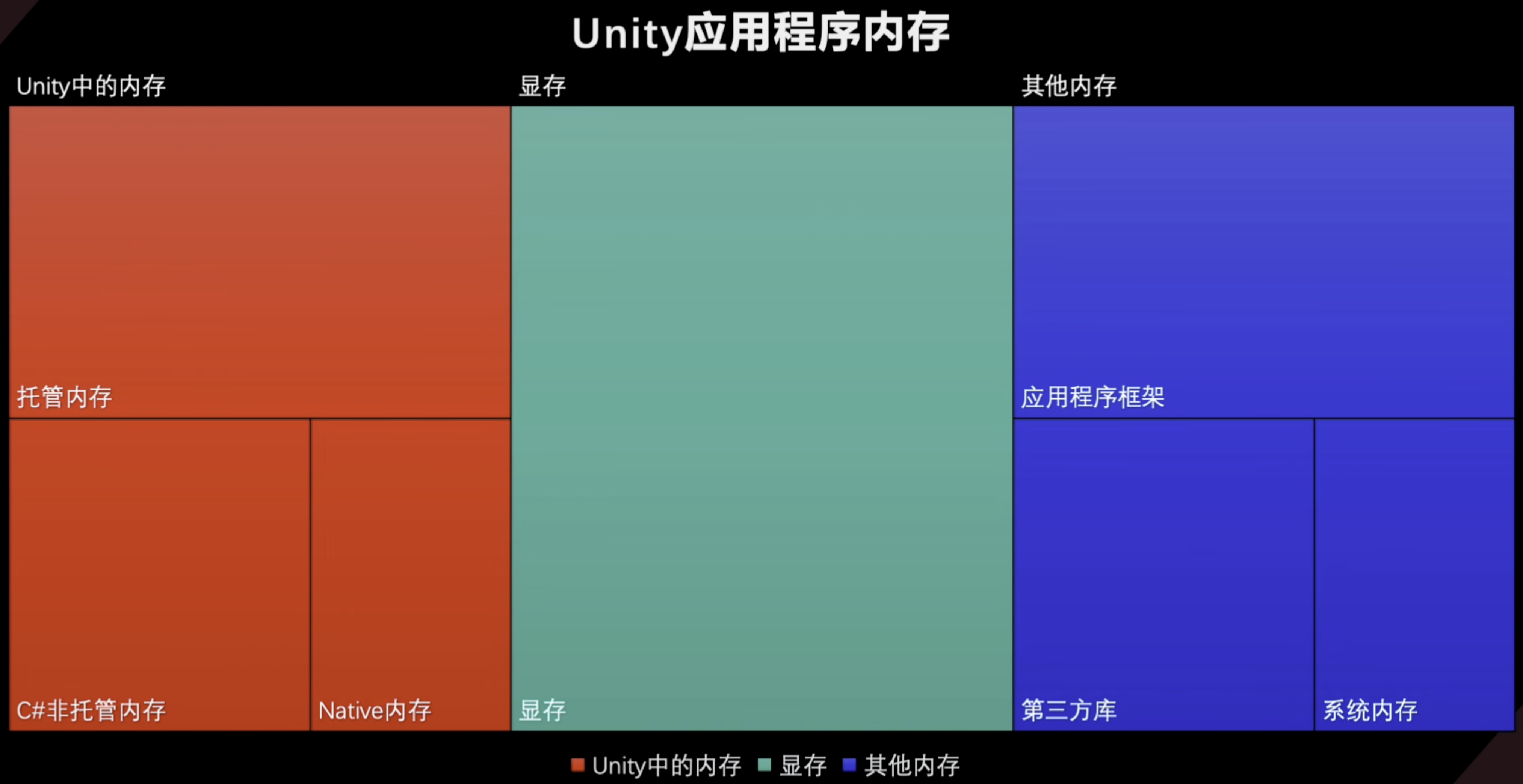
内存指标术语与进程内存结构
Page

- Used 配置正在被进程使用,内存页被影射到了物理内存中
- Free 该配置页可用,切该内存页没有被映射到物理内存中
- Cache 该页被操作系统用于缓存的可用内存,虽然被映射到物理内存中,但可能近期没有被访问,当Free Page数量低于一个阈值的时候,操作系统会从Cache的页中获取内存,并将cache中的数据交换到磁盘,然后对Cache的页进行清理,标记为 Free Page
在操作系统的更高层级上,还会讲page组织成区域
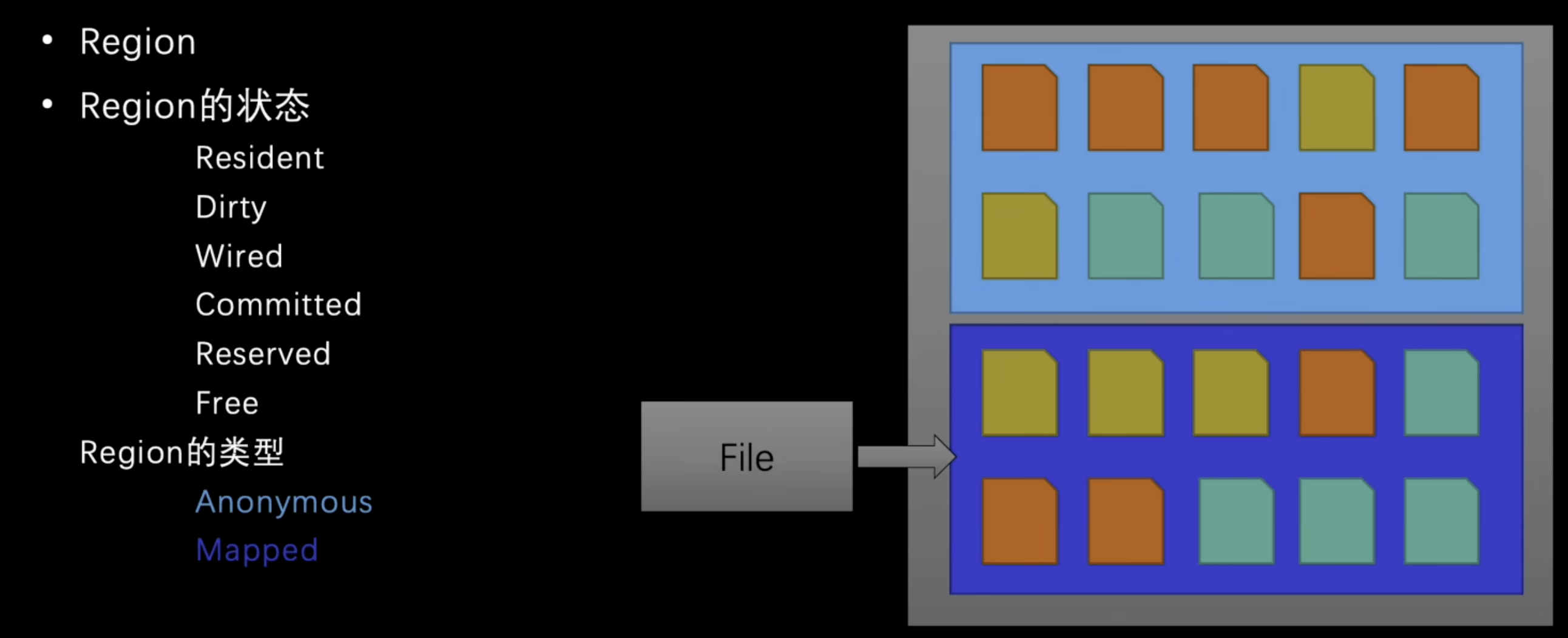
Region
Region状态
一块共享内存状态和保护级别的连续地址空间,可以由具有不同的页面状态的多个配置组成
- Resident 代表内存页已经在物理内存中
- Dirty 代表配置已修改,但未写入磁盘
- Wired 代表永远不会交换到辅助存储的固定配置段
- Commited 代表已分配的内存区域,其地址不能被其他分配使用,是由RAM、磁盘上的分页文件和其他资源来支持的。
- Reserved 该状态的 Region 保留地址空间供将来使用,地址不会被其他分配使用,也不可访问,尝试读写时会出现异常,也没有相关的物理存储支持
- Free 空闲内存区,既不会 Commited 也不会 Reserved,进程无法访问,访问该状态也会产生异常
Region类型
Anonymous 匿名,内存页与文件系统上的内存没有关联,如c++使用malloc的分配或mono的分配 Mapped 与文件系统设备节点关联的,文件与内存作直接映射
进程的内存结构
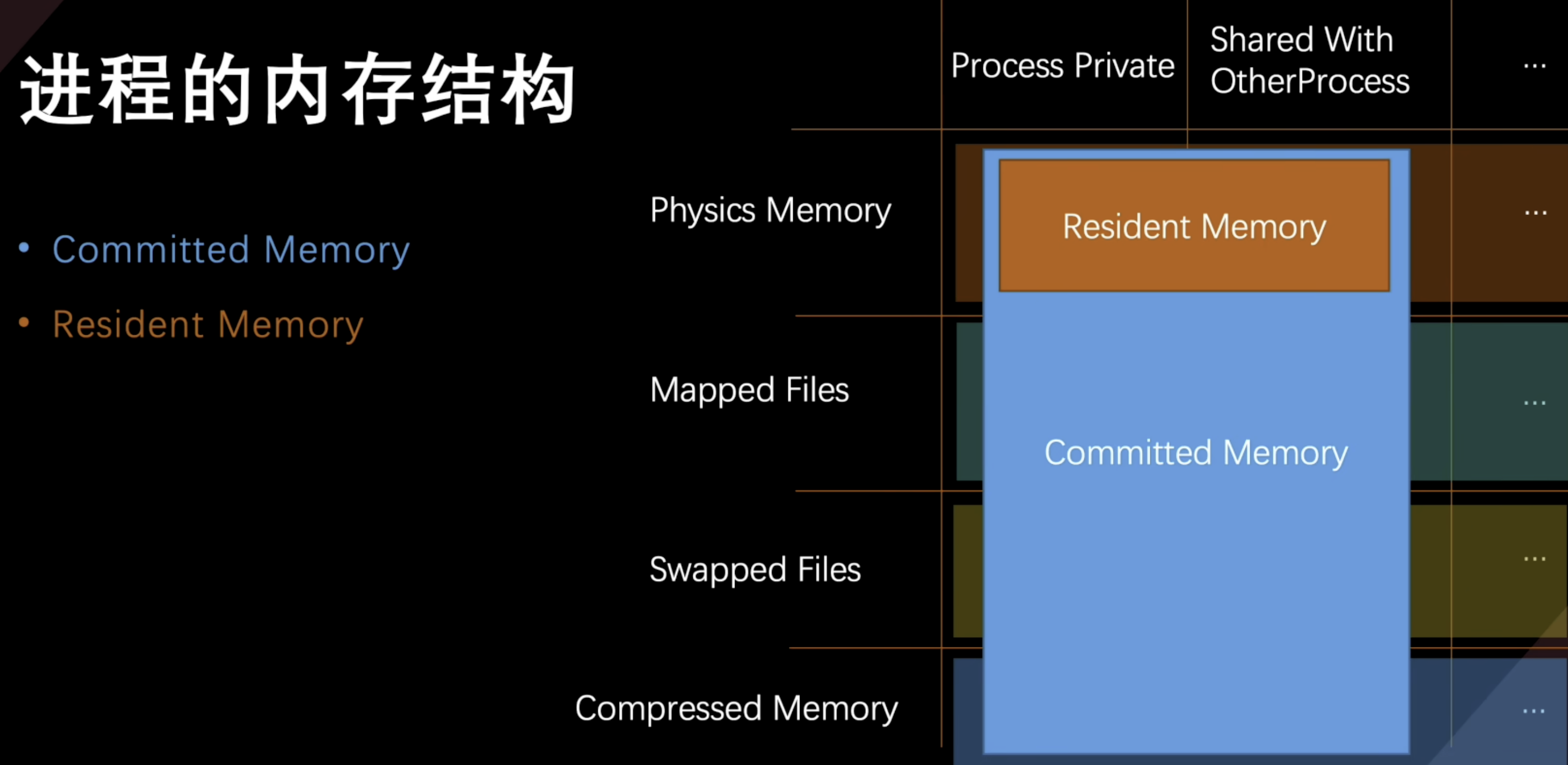
Commited Memory
一个进程内存的总量
Resident Memory
已经映射到虚拟内存中的物理内存,包括当前进程占用和其他进行的内存
进一步细分
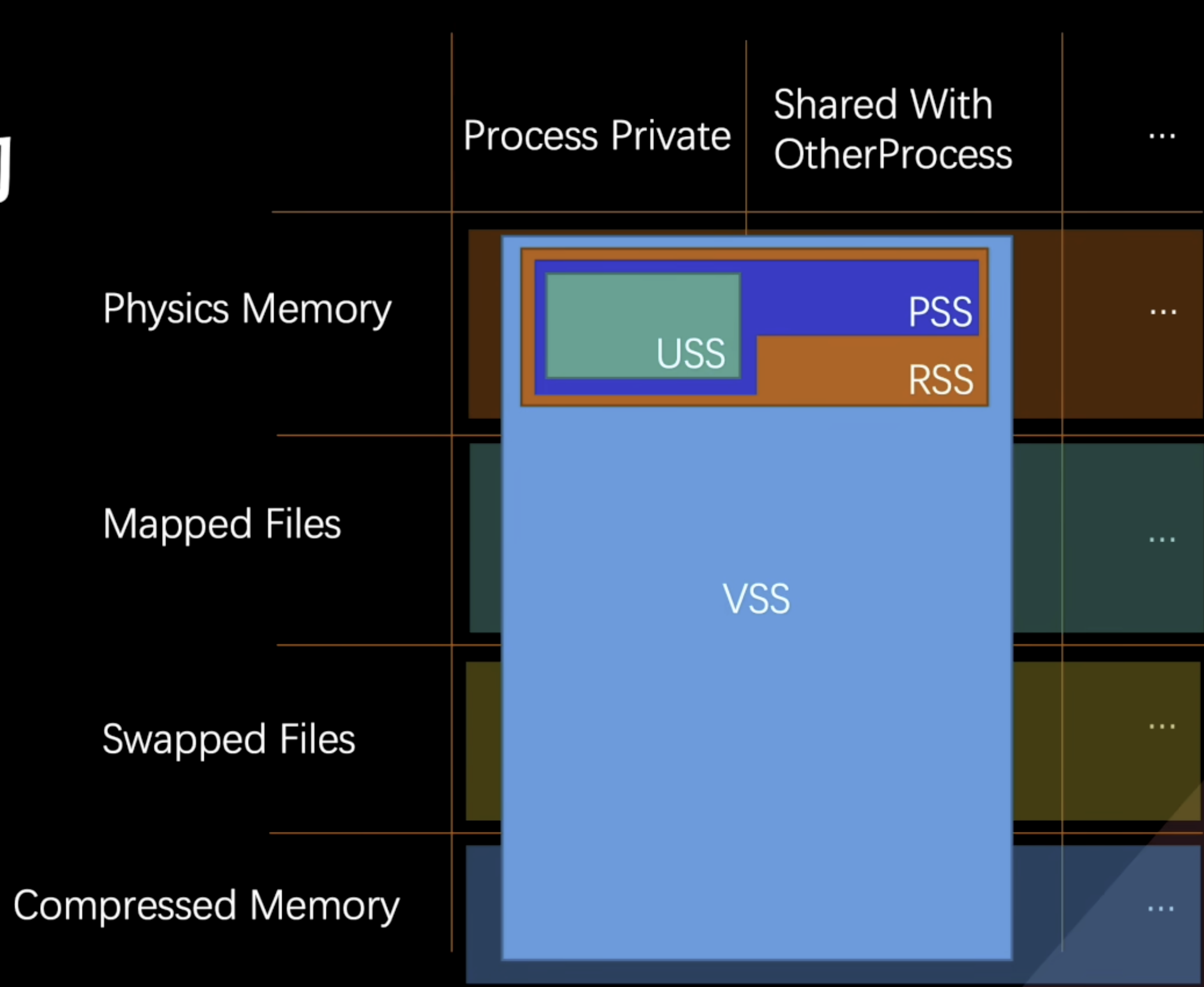
VSS
总共提交的Regions内存总和
USS
当前进程私有的Resident内存总和
PSS
当前进程常驻内存与其他进程共享的Resident内存总和
RSS
进程可访问的Resident长度内存总和
举例
Unity MemoryProfiler是以 VSS进行衡量的 Windows 管理器中 针对USS来衡量 XCode 衡量的是 RSS与压缩后的内存交换页的大小
移动平台内存经值数据分享
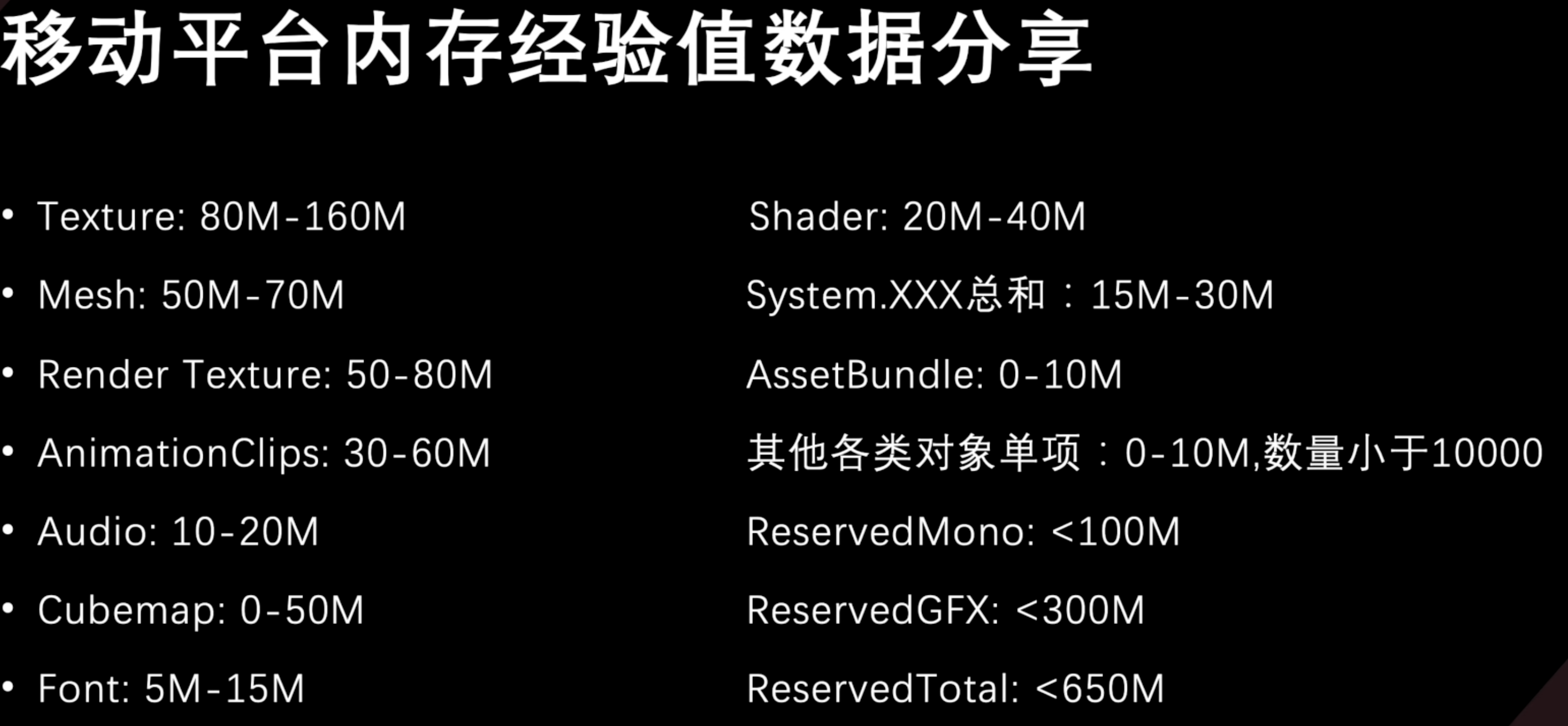 System.XXX 总和基本来自于用户的配置数据表与C#层基础类型变量的定义
通常是些文本数据,如果真的需要,建议使用二进制方式分级缓存读取
System.XXX 总和基本来自于用户的配置数据表与C#层基础类型变量的定义
通常是些文本数据,如果真的需要,建议使用二进制方式分级缓存读取
其他各类对象:一些C#层对象、Component和GameObject派生出来的对象
其他参考

Shader与托管内存优化
Shader的内存问题
超过50m就有必要了 引起内存问题的主要原因是Shader的 关键字过多,导致Shader的变体过多,打包的时候 变体剔除做的不好的话,会导致Shader的内存过高
三个问题
使用ShaderVariantCollection就万事大吉了吗? 我们有很牛云收集方案,肯定能将Shader变体收集完整 我们已经做了Shader变体剔除与收集,并对收集的变体做了Warmup,但还是会有运行时Shader加载编译情况
变体剔除与变体收集是两个不同的概念
变体剔除
让运行时 shader 内存占用更少,剔除不会被使用到的Shader变体
变体收集
为了做Shader的WarmUp,避免运行时shader加载编译导致的性能问题 可以用来辅助变体剔除工作,可以作为不被剔除的shader的参考
一般我们看Shader会产生多少变体,是通过 Shader 的Inspector面板来查看的 由于平台不同,我们需要切到不同平台上才能看到统计正确的变体数 我们还可以在 打包后的 Editor Log中搜索 Compiling shader 来查看每个shader的变体个数和实际打到包里的变体个数 shader在实际平台占用的内存还需要在移动设备上运行时,通过 Memory Profiler进行抓取查看
dynamic_branch
可以在不产生shader变体的情况下,运行时对shader进行动态分支判断,会产生一些gpu的额外开销。shader一个逻辑分支两条路径上 如果指令开销差异基本相同的情况下 可以用 dynamic_branch替代render_feature或multi_compile来定义shader关键字。建议看官方文档进行决定
假设
假设shader变体的个数是无限的,变体剔除和变体收集都是无法做到完全覆盖的。 这种情况下,我们只需要保证变体剔除 尽量干净,变体收集尽量完整即可
核心
Shader的Pass和关键字越少,shader变体剔除越好,内存占用就越小
托管内存优化
- Boxing Allocation装箱操作
- String字符串拼接,尽量使用stringbuilder
- 闭包分配 代码段中使用了代码段之外定义的变量,如lambda或匿名函数。调用这类代码段时,托管堆中会生成一个类来保存这些代码段中引用的外部变量
- 避免使用Linq库,会生成大量托管 堆上的垃圾内存 使用lua等脚本语言做热更新的开发者,在封装交互接口时,尽量不要传递unity引擎里定义的对象,最好传递基础类型值对象
Unity相关
- Unity中提供了 NonAlloc函数, 如Physics.RayCastAll用Physics.RayCastAlINonAlloc代替
- Unity.Object.FindObjectsOfType, UnityEngine.Component.GetComponentslnParent, UnityEngine.Component.GetComponentslnChild 等
- 成员变量访问方式 UnityEngine.Mesh.vertices=> UnityEngine.Mesh.GetVertices, UnityEngine.Mesh.uv=> UnityEngine.Mesh.GetUV UnityEngine.Renderer.sharedMaterials=> UnityEngine.Renderer.GetSharedMaterials Unity.lnput.touches=> Unity.lnput.GeTouches等
类似的函数还有很多,在调用时可以看看有没有对应的无托管函数进行替代
不要在循环或反复更新的逻辑中去反复Instantiate对象,尽量在初始化时,通过内存池提前预备好
当发现每帧GC变化过大的时候,可以开启BuildSetting Player 里的 Use Incremental GC,将一帧的GC调用分摊到多帧
强烈建议开启 Strip Engine Code,如果使用ILCPP,会删除不用的Unity引擎代码 Managed Stripping Level 根据包体和内存需求进行配置,删除托管dll中不使用的代码,一般hybridCLR不用